




The goal of this project is to make it simple and easy to farm. Since farming is tedious, providing an automated process to optimize crop yield allows Minecraft players to farm food in the background when they are not playing Minecraft. In our project, we are growing a single crop in a small 3x3 field. AI can be used to farm and plant faster and more efficiently. Unlike regular humans, AI knows the exact state of the field and can therefore harvest immediately when the crop is ready and immediately replant a seed in its place. This allows for a much higher crop yield in the same amount of time.

Originally, we implemented the q-learning algorithm with epsilon-greedy policy for choosing actions.

However, after running thousands of iterations and comparing our results for different values of epsilon, alpha, and gamma, we realized that the algorithm did not converge and the agent was only performing slightly better than the baseline of choosing entirely random actions.
Our main algorithm:
We are using Keras which is a Python Deep Learning Library. Keras is a high-level neural networks API, written in Python.
In Q-Learning Algorithm, we used the following algorithm which is used to approximate the reward based on a state. This algorithm calculates the expected future reward by using the current state and action. Similary in Deep Q network Algorithm, we use a neural network to approximate the reward based on the state.
There are some parameters that have to be passed to a reinforcement learning agent.
- num_reps = 30000 (number of games we want Steve to play)
- gamma = .95 (aka decay or discount rate, to calculate the future discounted reward)
- epsilon = 1.0 (aka exploration rate, this is the rate in which Steve randomly decides its action rather than prediction)
- epsilon_decay = .995 ( we want to decrease the number of explorations as Steve gets better at farming)
- epsilon_min = .01 (we want Steve to explore at least this amount)
- learning_rate = .001 (Determines how much neural net learns in each iteration)
The code below uses keras.models to create an empty neural net model:

The fit() method feeds input and output pairs to the model to train on those data to approximate the output based on the input. This makes the neural net predict the reward value from a certain state. After training, the model can predict the output from unseen input. When you call the predict() function on the model, the model will predict the reward of current state based on the data we trained.
We use the remember() function to maintain a list of previous experiences and observations to retrain the model with the previous experiences. This prevents the neural network from forgetting the previous experiences as it overwrites them with new experiences.

The replay() function trains the neural net with experiences in the memory. We are using a discount rate (gamma = .95) to make Steve maximize the future reward based on the given state.

Steve will randomly select its action at first by a certain percentage (exploration rate or epsilon). This is because it is better for Steve to first try all the actions before he starts to see patterns. When Steve is not deciding the action randomly, he will predict the reward value based on the current state and the harvest at age 4 action will give him the highest reward.
States:
For our starting farmland, we have a nxn block of land. Each block can be wheat or air (plant has already been harvested). There were originally 2^(nxn) possible states for whether or not the block has a plant. However, as the size of the field increased, there would be an exponential increase in the number of states. We manually keep track of the age (in seconds) of each plant when it is initially planted, instead of judging based on its visual appearance, to determine when is the right time to harvest since this data is not available on the Malmo platform. As a result, we have 6 states regardless of how large our field is: can_harvest_age_0, can_harvest_age_1, can_harvest_age_2, can_harvest_age_3, can_harvest_age_4, can_plant. If we decrease the growth rate, we can just increase the number of states linearly with the additional seconds it takes to grow.
Actions:
The actions are waiting, planting, and harvesting. For each of the seconds of age for the plant, we can choose a different action: harvest_
Reward Function:
Currently, the reward is based on the crop yield that the agent harvests and collects in its inventory. If the agent harvested the crop too early, then it will only get wheat seeds, leading to a negative reward. Waiting until the plant reaches full maturity will yield wheat, which results in a positive reward; otherwise, Steve is wasting time when he could be planting or harvesting something.
rewards_map = {‘wheat_seeds’: -40, ‘wheat’: 50}
actions_map = {“wait_not_empty”: -10, “planting”: -5}
Estimated Max Reward:
For a trial of 15 seconds, there is an average case that a crop will grow to full maturity in about 4 seconds. Harvesting takes 0.8 seconds, and planting takes 0.4 seconds, so the total time for a plant from planting to harvesting takes an average of 5.5 seconds. So there are about 15/5.2 cycles with each cycle having a reward of -5 (planting) and +50 (harvesting when ripe). In a 3x3 field, there would be an estimated max reward of 459(15/5.5) for a total of 1100. However, to account for any additional movements and calculations between actions, the estimated max reward would be 500.

Qualitatively, the project will solely be evaluated on how well Steve can harvest. It should know when to wait for the crop to fully be able to be harvested and when to plant. If Steve can achieve 90% of the expected max reward in that phase by the end of the iterations, it will be considered a success.
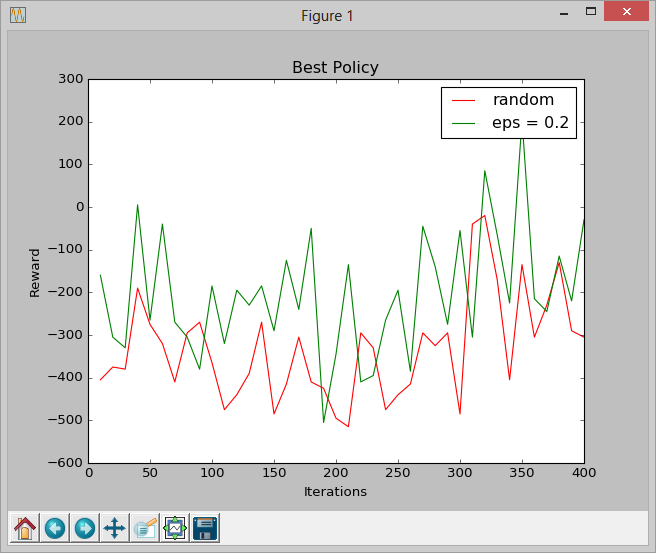
We started out using a q-learning algorithm and epsilon-greedy policy (eps = 0.2) for choosing actions, and compared the reward per iteration with a baseline of completely random actions. Although our agent performed better than the baseline, the algorithm did not converge so we never reached near the maximum possible reward.
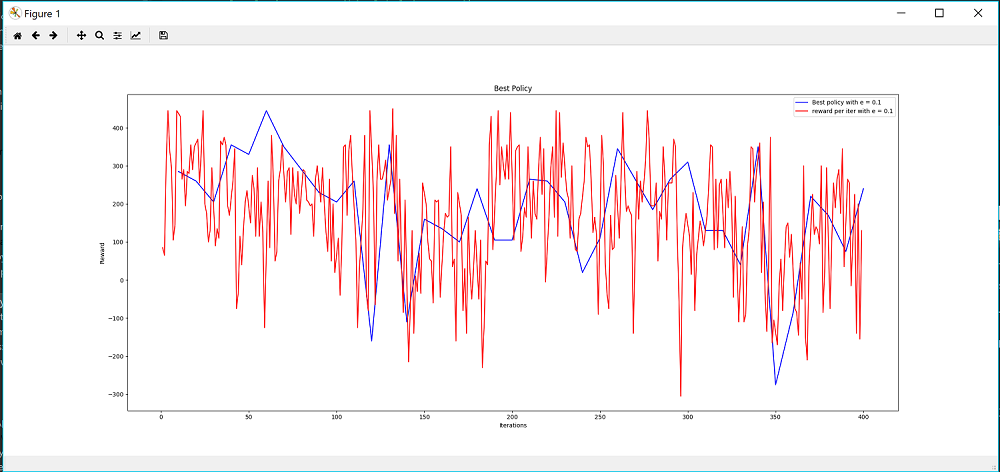
We also plotted the best policy reward with the reward per iteration for eps = 0.1 and noticed that the best policy was not always consistent with the highest reward achieved at that respective iteration, nor did the algorithm converge.
Epsilon = 0.1
Since Steve could not reach 90% of the expected max reward by the end of the iterations, we continued to play around with the parameters in the Q-learning algorithm and looked for more ways to fix this problem by switching to neural networks.
Here’s is a plot showing the learning trend of Steve using the neural network:
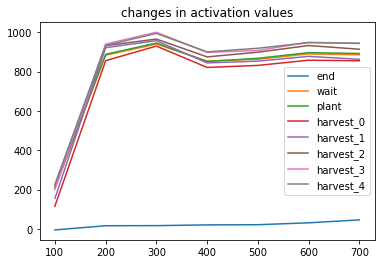
In the beginning, the agent explores by acting randomly. But as it goes through the multiple phases of learning, the agent learns that the best action is to harvest at age 4. The next best options are to plant or wait, with harvesting at age 0 and 1 being the worst actions. After several hundred iterations, we successfully trained Steve to be an excellent farmer.
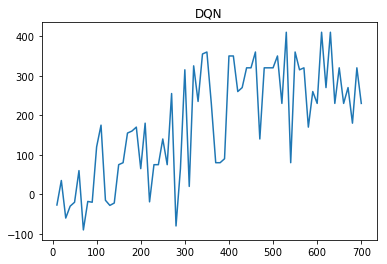
Here is a graph of Steve’s Performance using DQN: We were not able to reach our max estimated reward, but the alogorithm appears to plateau, and performs optimally. There could be additional time consumption that we are not taking into account.
References
Reinforcement Learning: An Introduction
Keras and Deep Q-Network Tutorial